In this chapter we use data comparing the birthweight of babies with smoking and nonsmoking mothers. First, after using Excel to sort the data, I stored it in R as smoker and nonsmoker.
smoker <- c(58, 65, 68, 69, 71, 71, 71, 72, 75, 75, 75, 75, 77, 77, 78, 80, 81, 81, 82, 82, 83, 84, 84, 85, 85, 85, 86, 86, 86, 86, 87, 87, 87, 87, 87, 87, 88, 88, 88, 88, 90, 90, 91, 91, 91, 91, 91, 91, 91, 92, 92, 92, 93, 93, 93, 93, 93, 93, 94, 94, 94, 94, 95, 95, 95, 96, 96, 96, 96, 96, 96, 96, 96, 96, 96, 97, 97, 97, 97, 97, 97, 97, 97, 98, 98, 98, 98, 98, 98, 98, 98, 99, 99, 99, 99, 99, 99, 99, 99, 99, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 101, 101, 101, 101, 101, 101, 101, 101, 101, 102, 102, 102, 102, 102, 102, 102, 102, 102, 103, 103, 103, 103, 103, 103, 103, 103, 103, 103, 103, 103, 103, 104, 104, 104, 104, 104, 104, 104, 104, 104, 104, 104, 105, 105, 105, 105, 105, 105, 105, 105, 105, 106, 106, 106, 106, 106, 106, 107, 107, 107, 107, 107, 107, 107, 108, 108, 108, 108, 108, 108, 108, 109, 109, 109, 109, 109, 109, 109, 109, 109, 109, 109, 109, 110, 110, 110, 110, 110, 110, 110, 111, 111, 111, 111, 111, 111, 112, 112, 112, 112, 112, 112, 113, 113, 113, 113, 113, 113, 113, 113, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 118, 118, 118, 118, 118, 118, 118, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 121, 121, 121, 121, 121, 121, 121, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 124, 124, 124, 124, 124, 124, 125, 125, 125, 125, 125, 125, 125, 125, 125, 126, 126, 126, 126, 126, 126, 126, 127, 127, 127, 127, 127, 127, 127, 127, 127, 128, 128, 128, 128, 128, 128, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 130, 130, 130, 130, 130, 130, 130, 130, 130, 130, 131, 131, 131, 131, 131, 131, 131, 131, 131, 132, 132, 132, 132, 132, 133, 133, 133, 133, 133, 133, 134, 134, 134, 134, 135, 135, 136, 136, 136, 136, 137, 137, 138, 138, 138, 138, 139, 139, 140, 140, 141, 141, 141, 141, 141, 142, 142, 143, 143, 143, 143, 143, 144, 144, 144, 144, 144, 144, 144, 144, 145, 145, 145, 145, 145, 146, 146, 148, 150, 150, 152, 152, 153, 154, 154, 154, 155, 156, 160, 160, 161, 163)
nonsmoker <- c(55, 62, 63, 65, 71, 71, 72, 73, 75, 78, 78, 79, 80, 81, 84, 84, 84, 85, 85, 85, 85, 87, 88, 89, 89, 90, 90, 91, 91, 91, 92, 93, 93, 93, 93, 94, 95, 96, 96, 97, 97, 97, 97, 97, 98, 98, 98, 98, 98, 99, 99, 99, 99, 99, 99, 99, 100, 100, 100, 100, 100, 100, 101, 101, 101, 101, 101, 102, 102, 102, 102, 102, 102, 102, 102, 102, 102, 103, 103, 103, 103, 103, 104, 104, 104, 104, 104, 104, 104, 105, 105, 105, 105, 105, 105, 105, 105, 105, 105, 105, 105, 105, 105, 106, 106, 106, 106, 106, 107, 107, 107, 107, 107, 107, 107, 107, 107, 108, 108, 108, 108, 108, 108, 108, 109, 109, 109, 109, 109, 109, 109, 109, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 110, 111, 111, 111, 111, 111, 111, 111, 111, 111, 111, 112, 112, 112, 112, 112, 112, 112, 112, 112, 112, 112, 112, 112, 112, 112, 112, 112, 112, 113, 113, 113, 113, 113, 113, 113, 113, 113, 113, 113, 113, 113, 113, 113, 113, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 114, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 115, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 116, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 117, 118, 118, 118, 118, 118, 118, 118, 118, 118, 118, 118, 118, 118, 118, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 119, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 120, 121, 121, 121, 121, 121, 121, 121, 121, 121, 121, 121, 121, 121, 121, 121, 121, 121, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 122, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 123, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 124, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 125, 126, 126, 126, 126, 126, 126, 126, 126, 126, 126, 126, 126, 126, 126, 126, 126, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 129, 130, 130, 130, 130, 130, 130, 130, 130, 130, 130, 130, 130, 131, 131, 131, 131, 131, 131, 131, 131, 131, 131, 131, 131, 131, 131, 131, 131, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 133, 133, 133, 133, 133, 133, 133, 133, 133, 133, 133, 133, 133, 134, 134, 134, 134, 134, 134, 134, 134, 134, 134, 134, 134, 134, 134, 135, 135, 135, 135, 135, 135, 135, 135, 135, 135, 135, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 137, 137, 137, 137, 137, 137, 137, 137, 137, 137, 137, 137, 137, 138, 138, 138, 138, 138, 138, 138, 138, 138, 138, 138, 138, 138, 138, 139, 139, 139, 139, 139, 139, 139, 139, 139, 139, 139, 139, 139, 140, 140, 140, 140, 140, 140, 140, 141, 141, 141, 141, 141, 141, 142, 142, 142, 142, 142, 142, 142, 143, 143, 143, 143, 143, 143, 143, 143, 144, 144, 144, 144, 144, 144, 144, 144, 144, 145, 145, 145, 145, 145, 146, 146, 146, 146, 146, 146, 146, 146, 147, 147, 147, 147, 147, 147, 148, 148, 148, 149, 149, 149, 150, 150, 150, 150, 150, 150, 151, 151, 152, 152, 152, 152, 153, 154, 154, 155, 155, 155, 155, 155, 156, 157, 158, 158, 158, 158, 159, 160, 160, 160, 162, 163, 163, 164, 165, 166, 167, 169, 170, 173, 174, 174, 174, 176)
Next I created a histogram for each set of data using the command hist(smoker) and hist(nonsmoker).


Next I used R to calculate the mean, standard deviation, median, quartiles, max, min, skewness and kurtosis of the two data sets. The mean of the data set is also known as the average. To calculate the mean in R I used the commands mean(smoker) and mean(nonsmoker). The standard deviation is the amount of variation there is in the data from the mean. To calculate the standard deviation I used the command sd(smoker) and sd(nonsmoker). The median of a data set is the value that is in the middle of a data set. I calculated the median by using the command median(smoker) and median(nonsmoker). The maximum and minimum are the highest and lowest values of a data set. To calculate the maximum and minimum I used the commands max(smoker), min(smoker), max(nonsmoker) and min(nonsmoker). The skewness of a data set is used to describe how the data is distributed. A skewness of zero means the data is relatively evenly distributed. A negative skewness means that most of the data including the median is to the right of the mean. A positive skewness means that most of the data including the median is to the left of the data. To calculate the skewness I used the command skewness(smoker) and skewness(nonsmoker). The kurtosis of a data set is the measure of whether it is peaked or flat. Data sets with a higher kurtosis usually have a peak near the mean and likewise data sets with a lower kurtosis generally have a more flat top. To calculate the kurtosis I used the command kurtosis(smoker) and kurtosis(nonsmoker). To calculate the skewness and the kurtosis the package “moments” must be installed into R and can be used using the command library(moments). A quartile is one of three points that divide the data into four groups that each represent 25% of the data. To calculate the quartiles I used the commands
duration=smoker
quantile(duration)
duration=nonsmoker
quantile(duration)
|
smoker |
nonsmoker |
| mean |
114.1095 |
123.0472 |
| standard deviation |
18.09895 |
17.39869 |
| median |
115 |
123 |
| max |
163 |
176 |
| min |
58 |
55 |
| skewness |
-0.03359498 |
-0.1869841 |
| kurtosis |
2.988032 |
4.03706 |
Quartiles:
|
0% |
25% |
50% |
75% |
100% |
| smoker |
58 |
102 |
115 |
126 |
163 |
| nonsmoker |
55 |
113 |
123 |
134 |
176 |




")
 Once the statistics for 2003 were removed from the data set the R-value was much higher and therefore much more reliable.
Once the statistics for 2003 were removed from the data set the R-value was much higher and therefore much more reliable.






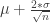



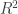 value. The Post Size data acts as the independent variable(x-axis) and the Pre Size data acts as the dependent variable(y-axis). Then the calculated R value will determine how close the data is to lying exactly on the regression line. If
value. The Post Size data acts as the independent variable(x-axis) and the Pre Size data acts as the dependent variable(y-axis). Then the calculated R value will determine how close the data is to lying exactly on the regression line. If  then the points lie exactly on the regression line and the sign indicates the slope of the line. If
then the points lie exactly on the regression line and the sign indicates the slope of the line. If  is close to
is close to  then the regression equation can be used along with the second set of Post Size Data to calculate a prediction for a set of Pre Size Data.
then the regression equation can be used along with the second set of Post Size Data to calculate a prediction for a set of Pre Size Data.

 . Therefore
. Therefore  . This R value is very close to
. This R value is very close to 



















{kind=link}